ファイル名の限界を調べる。
windows の人からもらった zip ファイルが 展開できなくて、ファイル名の長さの問題だったので、限界値(最大のファイル名の長さ)をぱぱぱっと調べた。
ファイルシステムごとに、ファイルの文字長(ファイルの文字サイズ)が違っていて、本当に困るんですよ。
日本語だと文字数ほとんど使えないLinux
Linuxはファイルの文字数が255バイトになっているので、日本語UTF-8のとき文字数が極めて少ない。
| フォーマット | 日本語の最大可能文字数 |
|---|---|
| ext4 | 85文字 |
| btfs | 85文字 |
| NTFS | 255文字 |
| exFAT | 255文字 |
UTF-8が3バイト前後というのはわかるのですが、85文字はマジでやばい。少なすぎませんかね。
これは、旧来のシステムと互換性切ってでも文字数はほしいところです。LinuxのSambaとかでファイル名が長くて保存されないってよくある問題。ずっと解決しないので、これから先も解決することな無いんだと思う。
カーネルコンパイル時にファイル名のサイズの上限を変えてコンパイルさせれば、ワンチャンあるけど、それした場合、アップデートどうすんの感。
ちなみに、Linuxから実験してるのでNTFSもexFATも Linuxでマウントしてます。マウントしてたら最大長突破できるのなら、ext4もマウントオプションで突破できるのではないかと思うんだけどね。
XFSやzfsは調べなかったけど、ex4と結果は同じです、同じ定数(NAME_MAX )見てるので。Linuxでマウントしてる限りは、255が適用されちゃう。
linux で現在の最大長を調べる
255 バイトと決まっているのだから、別に調べなくてもいいのだが。調べたいときは次のようにする。
getconf -a | grep -P '^NAME_MAX' NAME_MAX 255
実験に使用したコード
Linux環境で UTF8 で実行を前提に。
ファイル名の文字列の長さを調べていく。
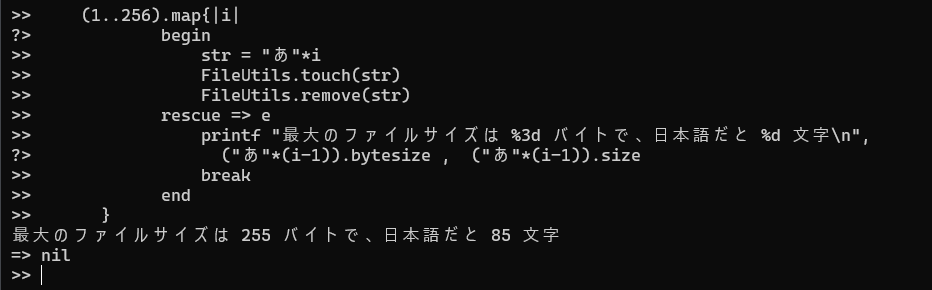
pwd = Dir.pwd.to_s (1..256).map{|i| begin str = "あ"*i FileUtils.touch(str) FileUtils.remove(str) rescue => e printf "最大のファイルサイズは %3d バイトで、日本語だと %d 文字\n", ("あ"*(i-1)).bytesize , ("あ"*(i-1)).size break end }
ディレクトリについても調べる
pwd = Dir.pwd.to_s (1..256).map{|i| begin pwd = Dir.pwd.to_s str = "/あ"*i FileUtils.mkdir_p(pwd+str) FileUtils.rm_rf(pwd+str) puts pwd+str rescue => e printf "最大のファイルサイズは %3d バイトで、日本語だと %d 文字\n", ("あ"*(i-1)).bytesize , ("あ"*(i-1)).size printf "パス名を含めた場合、最大のファイルサイズは %3d バイトで、日本語だと %d 文字\n", (pwd+'/'+"あ"*(i-1)).bytesize , (pwd+'/'+"あ"*(i-1)).size break end }
ext4 は 255バイト(UTF-8で85文字)で上限
ただしディレクトリは別カウント

btrfs も 85文字で上限

NTFS は「文字数」で255文字

exFAT は「文字数」で255文字

linuxのどこで定義されているのか。
cat /usr/include/linux/limits.h /* SPDX-License-Identifier: GPL-2.0 WITH Linux-syscall-note */ #ifndef _LINUX_LIMITS_H #define _LINUX_LIMITS_H #define NR_OPEN 1024 #define NGROUPS_MAX 65536 /* supplemental group IDs are available */ #define ARG_MAX 131072 /* # bytes of args + environ for exec() */ #define LINK_MAX 127 /* # links a file may have */ #define MAX_CANON 255 /* size of the canonical input queue */ #define MAX_INPUT 255 /* size of the type-ahead buffer */ #define NAME_MAX 255 /* # chars in a file name */ #define PATH_MAX 4096 /* # chars in a path name including nul */ #define PIPE_BUF 4096 /* # bytes in atomic write to a pipe */ #define XATTR_NAME_MAX 255 /* # chars in an extended attribute name */ #define XATTR_SIZE_MAX 65536 /* size of an extended attribute value (64k) */ #define XATTR_LIST_MAX 65536 /* size of extended attribute namelist (64k) */ #define RTSIG_MAX 32 #endif
btrfs とかは回避できなくもない。
btrfs でマウントしたボリュームをを、cifs/smb 経由でvfat でマウントし直せば。。。。できなくはないが後で地獄を見ることになる。
参考資料
cat /usr/include/linux/limits.h
https://serverfault.com/questions/9546/filename-length-limits-on-linux
