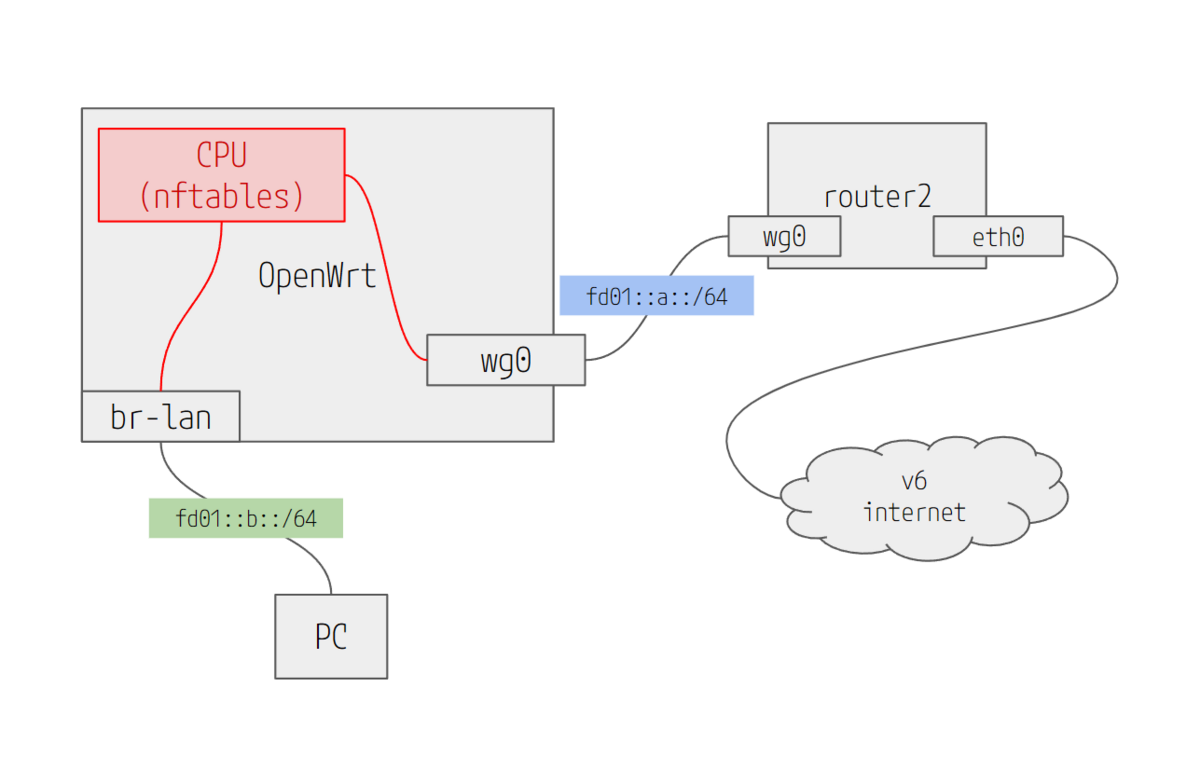
WEB-UI ( Luci )を使った場合
Luci で ip rule を作って ip route テーブルを作ることはできる。
前回やったコマンドからのポリシールーティングをLuCI(WEB)経由でやる話です。
やることは次の通り。
nftables でマークを扱う。
マーク済パケットをAcceptする。prerouting で マークする。ip rule でルーティングテーブルを分ける。
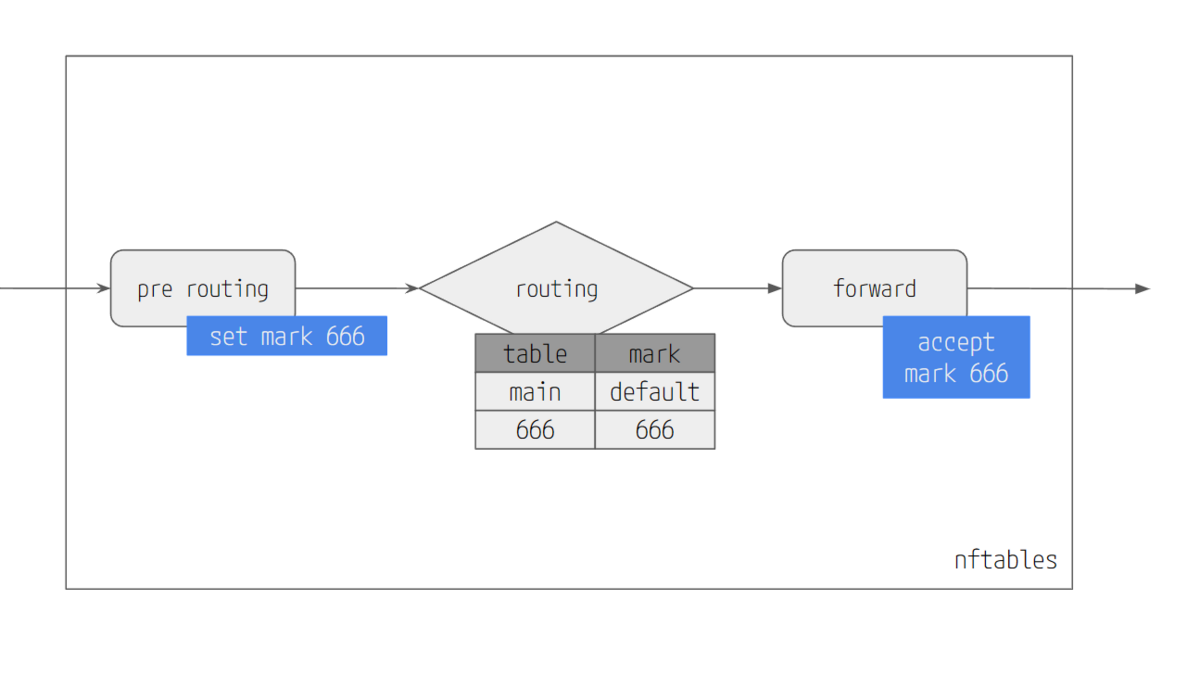
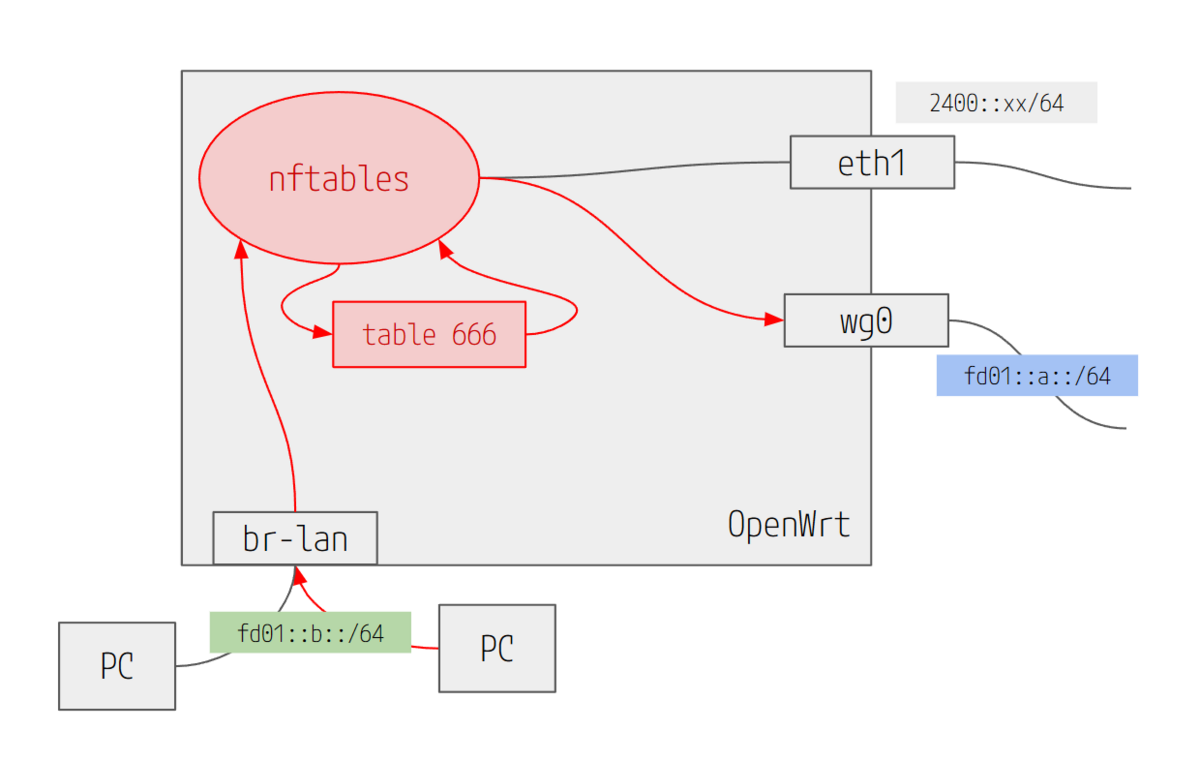
nftables のprerouting(マーク条件)を別テーブルにする
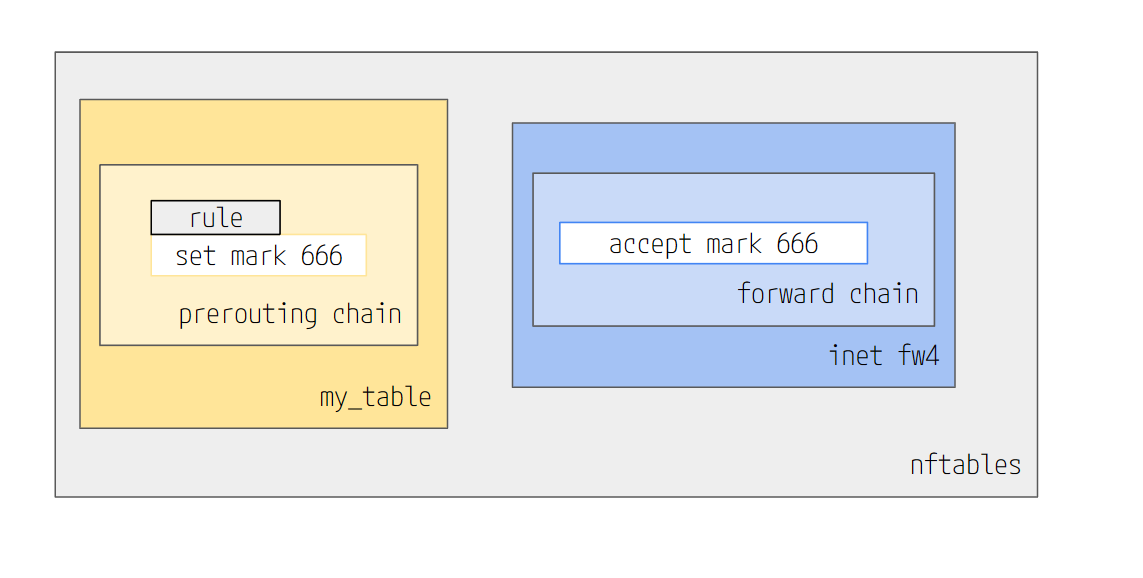
ポリシールーティング用のルーティングテーブル
ip rule 設定で、マーク済パケット専用のルーティングテーブルを作る。
設定の Neworking -> routing -> { Static IPv6 route , IPv6 Rule }を編集して次のような設定を作る。
IPv6 Routing の設定

IPv6 Rulesの設定

この結果、次のような設定が作られる。
config route6 option interface 'wg0' option target '2000::/3' option gateway 'fd00:aaa:afac:1919::1' option table '666' config rule6 option lookup '666' option mark '0x29a'
これで専用のルーティングテーブルを作ることができるし、MARKに一致したルールを作ることができる。
この結果はコマンドから確認できる。
ルールが作成される。
> ip -6 rule list 1: from all fwmark 0x29a lookup 666
ルーティングが設定される。
> ip -6 route show table 666 2000::/3 via fd00:aaa:afac:1919::1 dev wg0 proto static metric 1024 pref medium
ルーティングをテストする。(google.comのAAAA経路)
> GGv6=2404:6800:400a:80b::200e > ip -6 route get fibmatch $GGv6 mark 666 2000::/3 via fd00:aaa:afac:1919::1 dev wg0 table 666 proto static metric 1024 pref medium
マーク済パケットの経路が作られたことがわかった。
ファイアウォール設定で、マークを付ける。

config rule option name 'Add Mark' option family 'ipv6' list proto 'all' list src_ip 'fd03:3304:1128:3939::3' option target 'MARK' option set_mark '666' option src 'lan6' option dest '*'
ここで、ミスしちゃいけないのが、source zone をちゃんと入れること。
発信 zoneを入れると、 inet fw4 のmangle_preroutingにルールが作られる。
src zone を適当にAnyとかすると mangle_forwardやmangle_output に入ってしまう。悩ましい
この設定で、nft に次のルールが追加された
> nft list chain inet fw4 mangle_prerouting
table inet fw4 {
chain mangle_prerouting {
type filter hook prerouting priority mangle; policy accept;
iifname "br-lan" ip6 saddr fd03:3304:1128:3939::3 counter meta mark set 0x0000029a comment "!fw4: Add Mark"
}
}
指定したSRC Addr のパケットをマークしている。
マークしたパケットを許可する
マークをつけたパケットを、Forward許可する。

次のような設定ができる。
config rule option name 'Accept Mark' option family 'ipv6' option src '*' option target 'ACCEPT' option mark '666' list proto 'all' option dest '*'
この設定の結果として、nft に次のルールが追加される
> nft list chain inet fw4 forward
table inet fw4 {
chain forward {
type filter hook forward priority filter; policy drop;
meta nfproto ipv6 meta mark 0x0000029a counter accept comment "!fw4: Accept Mark" # これ
## 略
jump handle_reject
}
}
以上によって、マークしてパケットを流せる
OpenWrtLuCIの画面から、ファイアウォールでマークしたパケットを、転送することが出来た。
OpenWRT はいいおもちゃ。
設定がミスっていても、確認できるし。コマンドから強引にパケット通せるし。
やり方がわからないときは、コマンドで作ってから、同じ設定をLuCIで試せばいいし。
メーカ製品を使うと手当たり次第に試す羽目になり、どうしてもストレスを感じる。 マニュアルがあっても正解がわからないので難しい。
その点では、OpenWrtを使えばLinuxだしコマンドで行けるし、WRT限定事象かどうかもUbuntuやRaspiでも試したりでミスの発見を着実に歩みを進められるので本当に嬉しい。