送る方も、受け取る方も一番楽な写真の受け渡し方法
写真を受け渡す時に、色々とめんどくさい。Zipファイルにするのか。自己解凍形式にするのか、それとも、メールに複数添付するのか。
パスワードを付けたかったり、イベント事にまとめたかったり、サムネイルを付けたかったり・・・・
お悩みを一度に解決する方法があります。
PDFにするのです。
これを知った時は私も目から鱗が落ちる感じでした。そうかそうだよね。そうなんだよね。コロンブスの卵でした。
これ にすることで
- パスワードをかけられる
- ファイル名に悩まない。
- イベント毎に管理が楽
- プレビューペインで見られる
- フォルダ管理が楽
- 添付も楽
なんだ、これ。HTML化以上に素晴らしいじゃないか。
作り方
たったこれだけ!作り方も楽ちん
convert *.jpg my_album.pdf
convert コマンドは imagemagick に付属のコマンドです。これでPDFを作成できます。
出来上がったPDFはこんな感じ
AdobeReader で簡単に見られる。
 album
album
複数写真を一度に
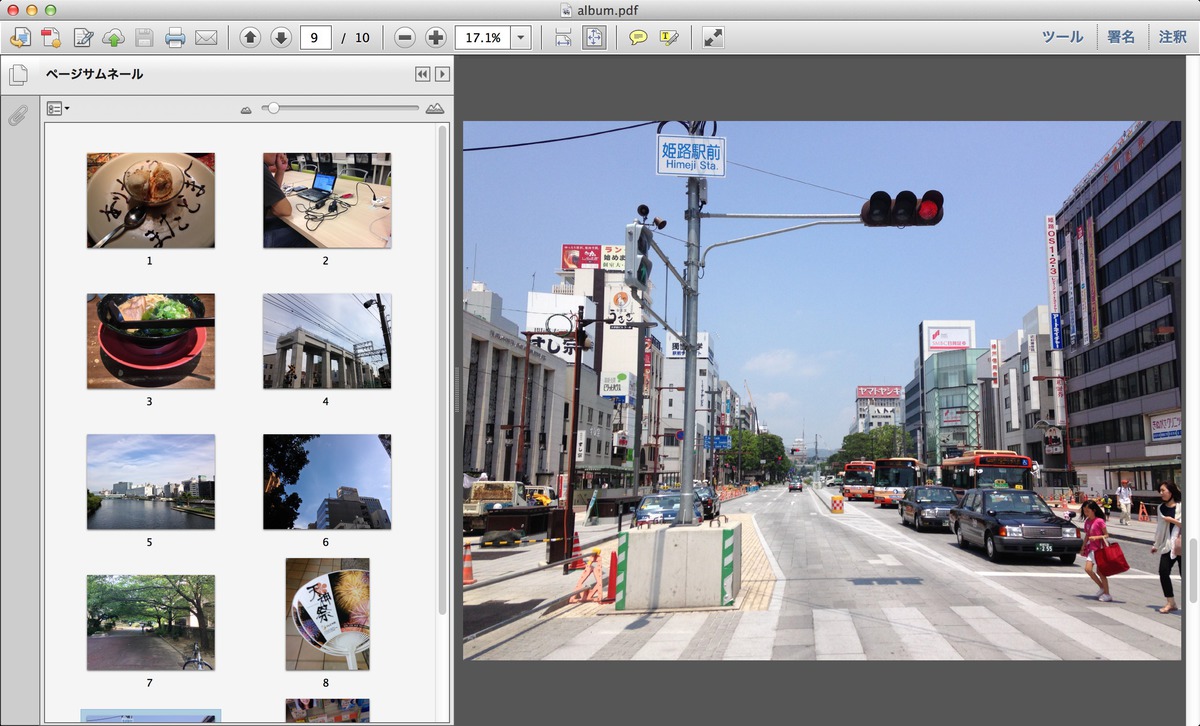 album
album
OSX のプレビューでも
サムネイル表示(左柱)
 album
album
コンタクトシートで一覧もできる
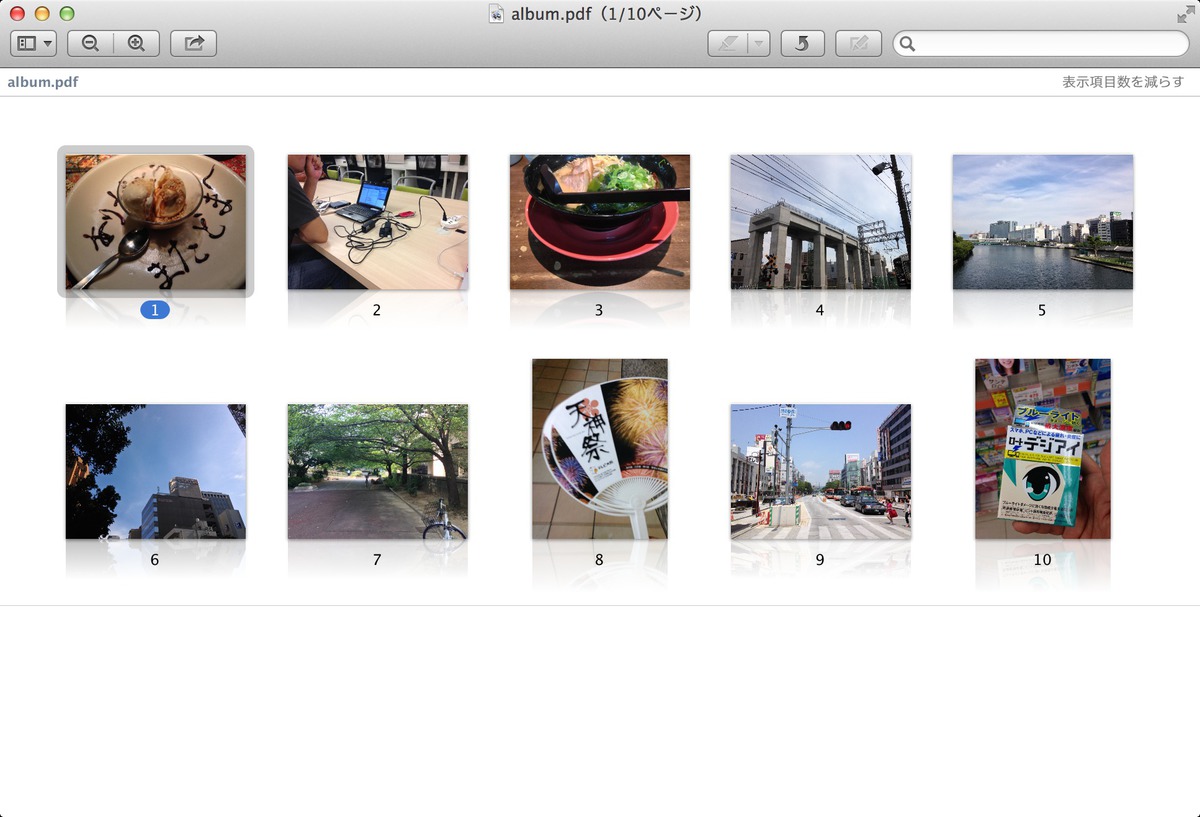 album
album
すごく便利だし、まとめているので紛失しない!
ちゃんとしたアルバムです。れっきとしたアルバムです。
注釈やメタデータもちゃんとファイルに書き込めます。
添付処理も楽ちん
メールやiMessageで添付するときやSkypeで送信するときも、PDFファイル一つにまとまっているので楽ちん!
細かいオプション
このコマンドだけだと、画質やファイルサイズの問題があるので・・・
convert *.jpg my_album.pdf
DPIで解像度指定や、画像圧縮、ページサイズ、リサイズを指定するともっと扱いやすい
convert *.jpg -density 100 -quality 100 -page 600x600 -resize 600x600 my_album.pdf
density : DPI解像度。デフォルト値は72、印刷用なら300以上かな
quality : JPEGの再圧縮率 0 が最高圧縮 100 が無圧縮
page : 1ページのサイズ(ピクセル)
resize : 貼り付け画像のサイズ(ピクセル)
更に開封用のパスワードを設定など
アルバムをそのまま渡すには、PDFにパスワードを設定するといい。画像ファイルをZIPで送るよりも、PDFにパスワードを追加したほうが安全だし相手も嬉しい。
pdftk album.pdf output out.pdf \ encrypt_128bit\ allow Printing CopyContents \ owner_pw my_password \ user_pw Passowrd123456
user_pw で開くときのパスワードを設定。このばあい「Passowrd123456」を指定。
allow と owner_pwとでPDFで閲覧印刷、編集などのパーミッションつけて改変を防ぐ
写真を送るときにzip ファイルでパスワードを付けるよりずっと楽ですね。
まとめ
convet コマンドとpdftk の組合せで、手軽にアルバムを作ることが出来る。
この他にも、PDFに注釈や製作者、またPDFなので、ページを追加して文章も貼り付けることが出来る。
メールであれこれ送るときに非常に便利に使えそうですね。
HTML文書中にPDF埋め込んだら業務上の文章が殆ど事足りそう。Excel方眼紙職人さんにドヤ顔できそう・・・
参考資料
元ネタは、PDF Hacksの本で教わりました。写真の配布に使うアイディアが一番心にグッときました。


更新
- 2020-04-16 Google検索でマッチしないので、表現を変更



